在余老師帶你學(xué)習(xí)大數(shù)據(jù)系列課程的第六章第二節(jié)中,我們將深入探討Spark編程模型與其基本架構(gòu),這是理解Spark如何實(shí)現(xiàn)快速大數(shù)據(jù)處理的關(guān)鍵。Spark之所以能在大數(shù)據(jù)領(lǐng)域脫穎而出,不僅因其卓越的性能,更得益于其精心設(shè)計(jì)的編程模型和高度可擴(kuò)展的架構(gòu)。本節(jié)將系統(tǒng)性地剖析這兩大核心要素,幫助讀者構(gòu)建清晰的知識(shí)框架。
Spark編程模型:簡(jiǎn)化并行計(jì)算
Spark編程模型的核心抽象是彈性分布式數(shù)據(jù)集(RDD,Resilient Distributed Dataset)。RDD是一個(gè)不可變、可分區(qū)的數(shù)據(jù)集合,能夠跨集群節(jié)點(diǎn)并行處理,并具備容錯(cuò)能力。這種模型將數(shù)據(jù)處理邏輯轉(zhuǎn)化為一系列轉(zhuǎn)換(Transformations)和行動(dòng)(Actions)操作,極大簡(jiǎn)化了分布式編程的復(fù)雜度。
核心操作類(lèi)型:
1. 轉(zhuǎn)換(Transformations):如map、filter、groupByKey等,它們基于現(xiàn)有RDD創(chuàng)建新的RDD,具有惰性求值特性,即不會(huì)立即執(zhí)行,而是記錄轉(zhuǎn)換關(guān)系,直到遇到行動(dòng)操作才觸發(fā)實(shí)際計(jì)算。
2. 行動(dòng)(Actions):如count、collect、saveAsTextFile等,它們觸發(fā)計(jì)算并返回結(jié)果或輸出數(shù)據(jù),是作業(yè)執(zhí)行的起點(diǎn)。
通過(guò)RDD及其操作,開(kāi)發(fā)者可以像編寫(xiě)本地集合程序一樣編寫(xiě)分布式代碼,而無(wú)需深入考慮數(shù)據(jù)分布、節(jié)點(diǎn)通信等底層細(xì)節(jié)。Spark在RDD基礎(chǔ)上發(fā)展了更高級(jí)的DataFrame和Dataset API,提供結(jié)構(gòu)化數(shù)據(jù)語(yǔ)義和優(yōu)化能力,進(jìn)一步提升了開(kāi)發(fā)效率與執(zhí)行性能。
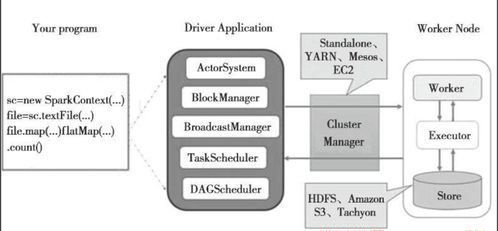
Spark基本架構(gòu):協(xié)同工作的組件生態(tài)
Spark采用主從(Master-Slave)架構(gòu),其核心組件協(xié)同工作,以實(shí)現(xiàn)高效的資源管理和任務(wù)執(zhí)行。主要組件包括:
- Driver Program(驅(qū)動(dòng)程序):
- 作為用戶(hù)程序的入口點(diǎn),負(fù)責(zé)定義RDD及其轉(zhuǎn)換/行動(dòng)操作。
- 將用戶(hù)程序轉(zhuǎn)化為有向無(wú)環(huán)圖(DAG),并通過(guò)DAG調(diào)度器將DAG分解為多個(gè)階段(Stages)和任務(wù)(Tasks)。
- 與集群管理器通信,申請(qǐng)資源并協(xié)調(diào)任務(wù)執(zhí)行。
- Cluster Manager(集群管理器):
- 負(fù)責(zé)集群資源的統(tǒng)一管理與分配。Spark支持多種集群管理器,包括Standalone(Spark自帶)、Apache Mesos和Hadoop YARN。
- 根據(jù)Driver的請(qǐng)求,為應(yīng)用分配Executor資源。
- Executor(執(zhí)行器):
- 在集群的工作節(jié)點(diǎn)上運(yùn)行的進(jìn)程,每個(gè)應(yīng)用有獨(dú)立的Executor。
- 負(fù)責(zé)執(zhí)行Driver分配的具體任務(wù),包括數(shù)據(jù)計(jì)算和存儲(chǔ)。
- 將緩存數(shù)據(jù)保存在內(nèi)存或磁盤(pán)中,加速迭代計(jì)算。
任務(wù)執(zhí)行流程:
- Driver將用戶(hù)程序解析為DAG,并劃分Stage(基于寬依賴(lài)劃分邊界)。
- Driver通過(guò)集群管理器啟動(dòng)Executor。
- Driver將Task分發(fā)給對(duì)應(yīng)的Executor執(zhí)行。
- Executor執(zhí)行Task,并將結(jié)果或狀態(tài)反饋給Driver。
- Driver收集最終結(jié)果或完成輸出操作。
架構(gòu)優(yōu)勢(shì)與數(shù)據(jù)處理效能
Spark架構(gòu)的核心優(yōu)勢(shì)在于其內(nèi)存計(jì)算與DAG調(diào)度優(yōu)化。通過(guò)將數(shù)據(jù)盡可能保留在內(nèi)存中,Spark避免了MapReduce等框架頻繁的磁盤(pán)I/O開(kāi)銷(xiāo),使得迭代算法和交互式查詢(xún)速度提升數(shù)十倍。DAG調(diào)度器能夠優(yōu)化任務(wù)執(zhí)行計(jì)劃,例如進(jìn)行流水線優(yōu)化,將多個(gè)窄依賴(lài)操作合并為一個(gè)Stage執(zhí)行,減少中間結(jié)果落盤(pán)。
Spark生態(tài)提供了Spark SQL(結(jié)構(gòu)化數(shù)據(jù)處理)、Spark Streaming(流計(jì)算)、MLlib(機(jī)器學(xué)習(xí))和GraphX(圖計(jì)算)等庫(kù),在統(tǒng)一編程模型下支持多樣化的數(shù)據(jù)處理場(chǎng)景,實(shí)現(xiàn)了“一站式”大數(shù)據(jù)分析。
###
掌握Spark編程模型與基本架構(gòu),是高效利用Spark進(jìn)行大數(shù)據(jù)處理的基石。編程模型通過(guò)高層抽象隱藏分布式復(fù)雜性,讓開(kāi)發(fā)者聚焦業(yè)務(wù)邏輯;而分層、協(xié)同的架構(gòu)設(shè)計(jì),結(jié)合內(nèi)存計(jì)算與智能調(diào)度,為快速處理海量數(shù)據(jù)提供了堅(jiān)實(shí)支撐。在后續(xù)學(xué)習(xí)中,我們將基于此基礎(chǔ),深入實(shí)踐如何利用Spark API解決實(shí)際數(shù)據(jù)處理問(wèn)題,充分發(fā)揮其在大數(shù)據(jù)時(shí)代的威力。